Cartographer Laser-SLAM 算法流程解析与调优
本篇博客的目的是记录自己在实物机器人上调试 Cartographer 算法的过程中,参考的资料和结合部分代码,一些自己总结的内容。Cartographer 是 Google 开源的一个激光 SLAM 项目,有着非常惊艳的工程实现。
本文参考 cartographer 官方文档。
首先要明确的一点,Cartographer 的官方文档也提到,这个 简介 仅仅给出直觉概述层面上的 Cartographer 的不同子系统的介绍和配置说明。如果为了更详细的描述和更严谨的表达,应该去看 Cartographer 的 Paper。虽然 Paper 中仅仅给出了 2D SLAM 的重要概念的严格表达,但这些概念可以非常自然的推广到 3D。
Paper:
W. Hess, D. Kohler, H. Rapp, and D. Andor, Real-Time Loop Closure in 2D LIDAR SLAM, in Robotics and Automation (ICRA), 2016 IEEE International Conference on. IEEE, 2016. pp. 1271–1278.
Cartographer Algorithm walkthrough for tuning
cartographer 基本思路简介
这篇 CSDN 博客说的挺简洁,但是现在必须成 VIP 才能看的文章了,有点醉… 主要两张图如下:
-
算法的基本思路
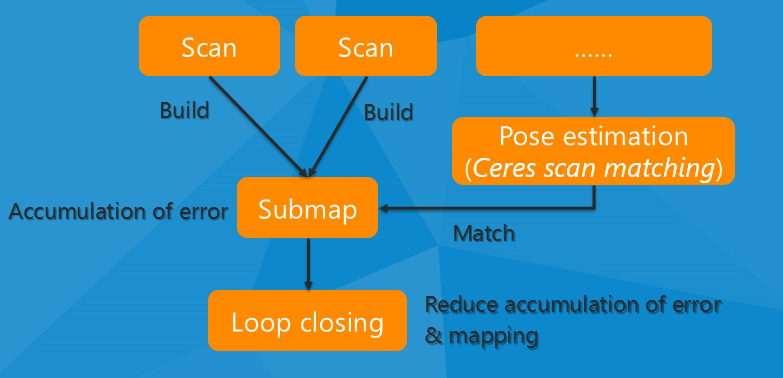
-
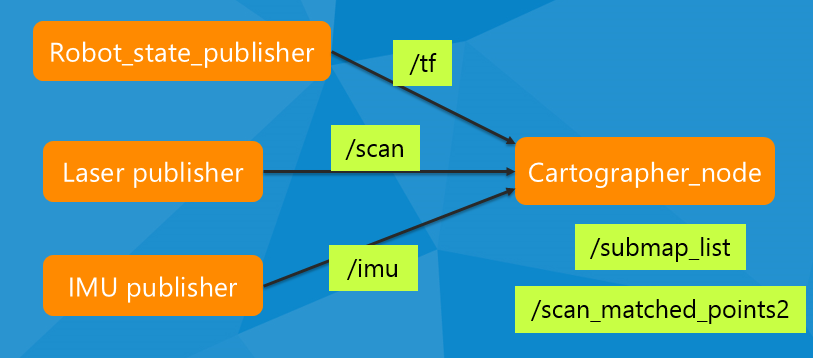
基本的 ROS 框架如下,当然可以有更多类型的输入,比如里程计信息等。
Cartographer 它的设计目标是实现低计算资源消耗,实时优化,不追求高精度(可以达到 r=5cm 级别的精度) Paper 中说了,它主要的贡献并不在算法层面,而是提供了工程上高效率、Robust 的代码实现。
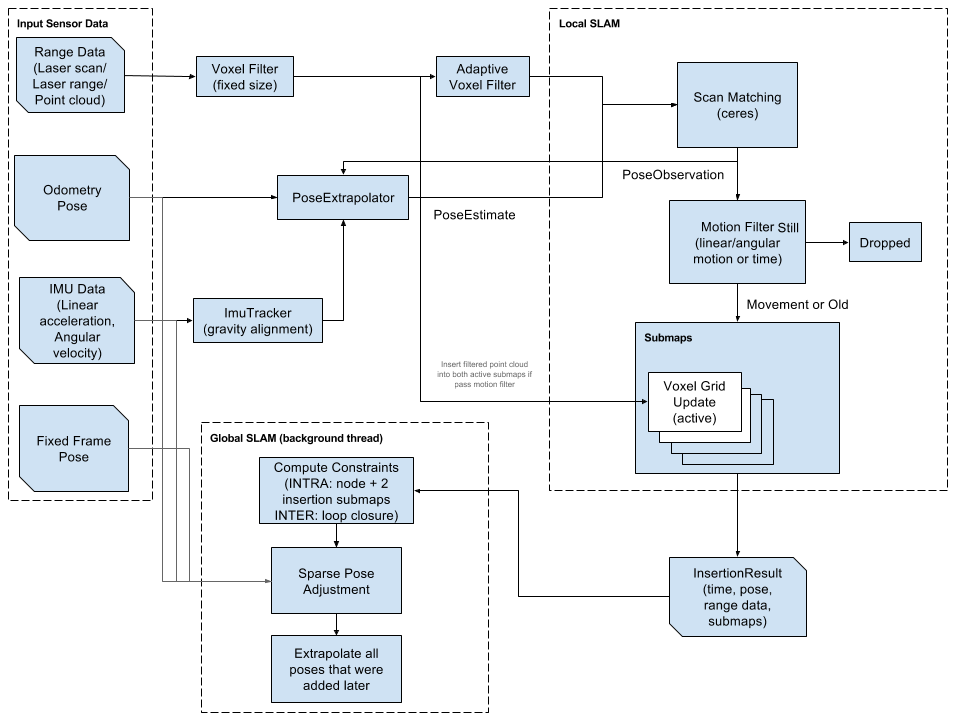
Cartographer 可以看做两个独立但有关系的子系统,Local SLAM 和 Global SLAM。
-
Local SLAM 可以被看做是前端 (local trajectory builder),任务是建立一个个的 submap。各个 submap 是本地一致的,但是会慢慢的漂移。Local SLAM 相关的配置文件是 trajectory_builder_2d.lua 或 trajectory_builder_3d.lua。后面用 TRAJECTORY_BUILDER_nD 表示相通的配置 options。
-
Golbal SLAM 是后端,单开了一个线程运行在后端,主要作用是寻找 loop closure constraints (回环约束)。通过 scans(gathered in nodes) 与 submaps 进行 matching 的方法来工作。并且可以结合其他传感器的数据来进一步提高精度,来确定一致性最强的 Global optimization 方案。3D SLAM 中还会尝试去估计重力方向。相关配置文件是 pose_graph.lua。
TODO:
- .lua 修改为本地 gitlab 仓库链接
- Global 中的 scans 和 nodes 的关系?scans(gathered in nodes)
总的来说,Local SLAM 的主要工作是生成更好的 submaps,Global SLAM 的工作是将这些 submaps 更好的结合起来。
Input Process
Laser Data
注意!Cartographer 中关于距离的参数的单位均为 米 /m
由于在实际运用的过程中,雷达在机器人身上的安装位置导致雷达被机器人身上其他部件挡了、或者雷达自身落灰了,或者一些从不期望的来源得到的最远的测量值(比如反射、或者自身传感器噪声)等,都是 SLAM 过程中所不期望的。对于这些噪声,Cartographer starts by applying a bandpass filter and only keeps range values between a certain min and max range。下面的这俩值根据你机器人和雷达的实际情况来确定。
这两个参数就是雷达扫描数据的距离范围。参数为下面两个。
1 | |
Cartographer 会用TRAJECTORY_BUILDER_2D.missing_data_ray_length的值来替换实际大于TRAJECTORY_BUILDER_nD.max_range 的 ranges。
TODO:
考虑根据具体的自己机器人的形状和雷达的实际效果,确定更好的卡值的方法?但又仔细一想好像又没这必要。
TRAJECTORY_BUILDER_2D.missing_data_ray_length参数的说法还是有点迷… 代码中是这样写的:
cartographer/mapping/internal/2d/local_trajectory_builder_2d.hline: 170-189
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Drop any returns below the minimum range and convert returns beyond the
// maximum range into misses.
for (size_t i = 0; i < synchronized_data.ranges.size (); ++i) {
const Eigen::Vector4f& hit = synchronized_data.ranges [i].point_time;
const Eigen::Vector3f origin_in_local =
range_data_poses [i] *
synchronized_data.origins.at (synchronized_data.ranges [i].origin_index);
const Eigen::Vector3f hit_in_local = range_data_poses [i] * hit.head<3>();
const Eigen::Vector3f delta = hit_in_local - origin_in_local;
const float range = delta.norm ();
if (range>= options_.min_range ()) {
if (range <= options_.max_range ()) {
accumulated_range_data_.returns.push_back (hit_in_local);
} else {
accumulated_range_data_.misses.push_back (
origin_in_local +
options_.missing_data_ray_length () /range * delta);
}
}
}具体待跑起来后分析实际数据
如果将 3D 雷达用在 2D SLAM 的话,提供一个 “截断” 的参数,就是把一定高度范围内的扫描点映射到 2D 的一个平面上。
1 | |
一组激光雷达的距离数据是一段时间内测量出来的,而这一段时间内机器人是运动的,这就导致了激光数据会产生畸变。这些距离数据被封装到一帧一帧的 ROS message 中,每一帧都带有时间戳信息,Cartographer 会把多 (>=1) 帧集合 (accumulate) 成一个大帧作为算法的输入。Cartographer 认为这每一帧都是独立的,以帧为单位补偿运动导致的激光雷达数据产生的畸变,然后再把这些帧集合到一块去。所以当然 Cartographer 接收到的数据帧的频率越高,Cartographer 的补偿效果越好,算法的输入数据质量越高。
所以 TRAJECTORY_BUILDER_nD.num_accumulated_range_data 参数的意义就是集合多少帧运动补偿后形成算法输入的大数据帧。(该参数要根据实际雷达的数据采集频率和每一帧数据的扫描范围来定,比如 Rplidar A3 的一帧数据是采样一圈;而 VLP-16 的一帧数据可以调成一个 udp 数据包而不是一圈数据,并且这样更好,因为转一圈也是需要时间的,这样就可以把一圈内的数据也做了运动补偿)
相关代码 (cartographer/mapping/internal/2d/local_trajectory_builder_2d.h line:142-205):
1 | |
Voxel Filter
较近的表面 (如路面) 经常扫描得到更多的 points, 而远处的物体的 points 经常比较稀少。为了降低计算量,需要对点云数据进行下采样,简单的随机采样仍然会导致低密度区的点更少,而高密度区的点仍然比较多。因此 cartographer 采用 voxel_filter (体素滤波) 的方法。通过输入的点云数据创建一个三维体素栅格(可把体素栅格想象为微小的空间三维立方体的集合),然后在每个体素(即,三维立方体)内,用体素中所有点的重心来近似显示体素中其他点,这样该体素就内所有点就用一个重心点最终表示,对于所有体素处理后得到过滤后的点云。TRAJECTORY_BUILDER_nD.voxel_filter_size 即为立方体的大小。如果立方体较小的话会导致更密集的数据,所耗的计算量更大。而较大的话可能会导致数据丢失但是计算速度会更快。
在提供了定大小的 voxel_filter, Cartographer 还提供了一个 adaptive_voxel_filter, adaptive_voxel_filter 可以在最大边长 TRAJECTORY_BUILDER_nD.adaptive_voxel_filter.max_length 的限制下优化确定 voxel_filter_size 来实现目标的 points 数 TRAJECTORY_BUILDER_nD.adaptive_voxel_filter.min_num_points 。
官方给的默认配置:
trajectory_builder_2d.lua
1 | |
trajectory_builder_3d.lua
1 | |
IMU Data
IMU 对于 SLAM 可以提供非常有用的信息,Cartographer 直接利用 IMU 所提供的三轴线加速度与角速度信息,可以提供一个较为精确的重力方向,以及提供带有噪声但是整体方向大概正确的关于机器人旋转的信息。为了滤掉 IMU 的噪声,gravity is observed over a certain amount of time。在 2D SLAM 中,可以做到无外界的一些补充信息来源而实时处理数据,所以 2D SLAM 可以选择是否使用 IMU 的消息。但是在 3D SLAM 中需要提供 IMU 数据作判断 scans 方向的先验,可以大大降低 scan 匹配的复杂性。
cartographer 中关于时间的参数单位均为 s (秒).
1 | |
下文 imu 数据还在 Global optimization 中的应用.
Local SLAM
Once a scan has been assembled and filtered from multiple range data, it is ready for the local SLAM algorithm. Local SLAM 可以利用来自与 pose extrapolator 的输出信息作为一个先验,把一帧新的 scans 通过 scan matching 的方法插入到当下的 submap 中。使用 pose extrapolator 的 idea 是,通过除了激光雷达以外的传感器的数据来预测当前 scan 插入到 submap 的位置,比如里程计信息、IMU 等。
Two scan matching strategies
CeresScanMatcher 以及 RealTimeCorrelativeScanMatcher
-
CeresScanMatcher 利用上面说的先验 initial guess , 寻找 scan 与当前的 submap 最匹配的位置。通过对 submap 进行插值然后与 scan 进行对齐(It does this by interpolating the submap and sub-pixel aligning the scan)。这种做法比较快速,但是无法修复远大于子图分辨率的误差。如果你的传感器的设置与累积的那个时间区间都是合理的话,仅仅使用 CeresScanMatcher 通常是最好的选择。
CeresScanMatcher 可以为每一个输入源配置一个权重 weight,权重就是对其数据的信任度,可以把它视为静态协方差。这个 weight 是无量纲的,并且是不能相互比较的。weight 越大,Cartographer 在进行 scan matching 的时候就对他更关注。数据来源可以包括 occupied space (points from the scan), translation and rotation from the pose extrapolator (or
RealTimeCorrelativeScanMatcher)1
2
3
4
5TRAJECTORY_BUILDER_3D.ceres_scan_matcher.occupied_space_weight
TRAJECTORY_BUILDER_3D.ceres_scan_matcher.occupied_space_weight_0
TRAJECTORY_BUILDER_3D.ceres_scan_matcher.occupied_space_weight_1
TRAJECTORY_BUILDER_nD.ceres_scan_matcher.translation_weight
TRAJECTORY_BUILDER_nD.ceres_scan_matcher.rotation_weightIn 3D, the
occupied_space_weight_0andoccupied_space_weight_1parameters are related, respectively, to the high resolution and low resolution filtered point clouds.CeresScanMatcher 的名字来源于 Ceres Solver。这个 scan matching 问题被建模为一个最小二乘问题,两帧间的 motion 是待优化变量。(GN 等方法)Ceres optimizes the motion using a descent algorithm for a given number of iterations. Ceres can be configured to adapt the convergence speed to your own needs.
1
2
3TRAJECTORY_BUILDER_nD.ceres_scan_matcher.ceres_solver_options.use_nonmonotonic_steps
TRAJECTORY_BUILDER_nD.ceres_scan_matcher.ceres_solver_options.max_num_iterations
TRAJECTORY_BUILDER_nD.ceres_scan_matcher.ceres_solver_options.num_threadsuse_nonmonotonic_steps这个暂时还未深究,参见 Ceres-Solver 官方文档讲解官方给的默认配置:
trajectory_builder_2d.lua1
2
3
4
5
6
7
8
9
10
11
12
13
14TRAJECTORY_BUILDER_2D = {
...
ceres_scan_matcher = {
occupied_space_weight = 1.,
translation_weight = 10.,
rotation_weight = 40.,
ceres_solver_options = {
use_nonmonotonic_steps = false,
max_num_iterations = 20,
num_threads = 1,
},
},
...
} -
RealTimeCorrelativeScanMatcher 在你比较不信任你的其他传感器或者不存在其他的传感器的情况下可以启用。它的做法类似于回环检测中的做法将 scan 与当前 submap 进行 match。Best match 然后被用作 CeresScanMatcher 的先验。这种 match 的方式对计算资源要求较高,并且开了后,就忽略了其他传感器的数据。但这种做法在 feature rich 的环境中的鲁棒性非常好。
同样 RealTimeCorrelativeScanMatcher 也可以根据对 sensors 的信任度进行配置 (即可以配置不同权重 / 置信度 /weight)。它的工作原理是在一个搜索窗口中 (搜索窗口的大小由搜索的最大距离半径和角度范围来指定)。在此窗口中进行 scan match 的时候,可以为 translation 和 rotation 选择不同的权重。
TODO
例如当已知机器人不会旋转过多的话,就可以改变对应 weight。
所以这个 weight 到底是指?具体还是看代码吧
1
2
3
4
5TRAJECTORY_BUILDER_nD.use_online_correlative_scan_matching
TRAJECTORY_BUILDER_nD.real_time_correlative_scan_matcher.linear_search_window
TRAJECTORY_BUILDER_nD.real_time_correlative_scan_matcher.angular_search_window
TRAJECTORY_BUILDER_nD.real_time_correlative_scan_matcher.translation_delta_cost_weight
TRAJECTORY_BUILDER_nD.real_time_correlative_scan_matcher.rotation_delta_cost_weight官方给的默认配置:
trajectory_builder_2d.lua1
2
3
4
5
6
7
8
9
10
11TRAJECTORY_BUILDER_2D = {
...
use_online_correlative_scan_matching = false,
real_time_correlative_scan_matcher = {
linear_search_window = 0.1,
angular_search_window = math.rad (20.),
translation_delta_cost_weight = 1e-1,
rotation_delta_cost_weight = 1e-1,
},
...
}
motion_filter
为避免将过多的 scan 插入到 submap 里,当两个 scan 成功 match 后,会得到两个 match 之间的运动关系。当两者运动关系不明显的话,这个 match 结果就不会被插入到 submap 中去。这个操作通过运动滤波器中卡 time,distance 以及 angle 的阈值来实现。
1 | |
官方给的默认配置:
trajectory_builder_2d.lua
1 | |
Submap
当 Local SLAM 接收到一定数量的 range data 时可认为此时当前的 submap 被完成了,这个即由 TRAJECTORY_BUILDER_nD.submaps.num_range_data 参数来指定。Local SLAM 的结果在时间上积累后会产生漂移误差,Global SLAM 可以来 fix 这个误差。这个 Submap 必须足够的小从而可以认为它是局部正确的。但从另一方面来看,他又必须足够的大从而可以做回环。
1 | |
这里总结一下,雷达数据到建图的流程如下:

Submap 可以采用不止一种的数据结构来存储。但是现在大多都是采用的概率栅格地图(probability grids)的方式来存储。但是在 2D 中,还可以采用 TSDF(Truncated Signed Distance Fields)地图类型。
1 | |
概率栅格地图的资料很多,去搜一下即可。这里就贴文档原句了。Odds are updated according to “hits” (where the range data is measured) and “misses” (the free space between the sensor and the measured points)。可以根据对被占据 occupied 和 free space 的雷达数据的置信度,加减 hits 和 misses 的 weight 值(Both hits and misses can have a different weight in occupancy probability calculations giving more or less trust to occupied or free space measurements)。
TODO
这里为啥分了两个… 是因为不同的地图类型吗
1 | |
官方给的默认配置:
trajectory_builder_2d.lua
1 | |
2D SLAM 中一个 submap 仅有一个栅格地图(probability grid)被存储。在 3D SLAM 中因为 scan matching 性能的原因,维护了两个 hybrid probability grid (the term “hybrid” only refers to an internal tree-like data representation and is abstracted to the user),并分别应用了一个 adaptive_voxel_filter:
- 一个是用于远距离测量的低分辨率 hybrid grid
- 另一个是用于近距离测量的高分辨率 hybrid grid
Scan match 首先将远处的低分辨率的点云与低分辨率 hybrid grid 对齐,然后通过高分辨率的近处点云与高分辨率的 hybrid grid 对齐来 refine pose。
1 | |
TODO
上面的 adaptive_voxel_filter.max_range 是指的近和远的距离的界定吗
Cartographer ROS 提供了一个可以在 rviz 中可视化 submaps 的插件。可以选择 submap 通过他们的 id。3D SLAM 中 rviz 仅仅显示 3D hybrid probability grids 的 2D 投影(in grayscale)。通过 Rviz 左侧栏可以切换 high resolution hybrid grids 来看。
trajectory_builder_3d.lua
1 | |
Global SLAM
当 Local SLAM 成功生成 submaps 的同时,在后端运行着一个全局的优化程序(sparse pose adjustment)。通过调整 submap 的位置来保持全局一致。然后还会考虑回环优化。
每当 POSE_GRAPH.optimize_every_n_nodes 数目的 node 被插入地图的时候运行一次 optimization。
通常先将 POSE_GRAPH.optimize_every_n_nodes 置零来关闭 Global SLAM,然后专心的来调 Local SLAM。这通常是调试 Cartographer 的第一步。
我们把估计出来的一个 Scan 的绝对位姿称为 trajectory 上的一个节点 (Node),那么节点与节点的彼此之间的相对位姿就可以称为一个约束 (Constraint)。参考链接
上面的说法的确比较容易理解,并且做 Pose Graph 的确仅依赖与位姿。但是通过代码来看,这个 Node 所带的信息不止有 Scan 的绝对位姿(gravity aligned,用代码中的注释:Transform to approximately gravity align the tracking frame as determined by local SLAM.),还带有 gravity aligned 的 PointCloud。
trajectory_node_data.proto 文件:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19syntax = "proto3";
package cartographer.mapping.proto;
import "cartographer/sensor/proto/sensor.proto";
import "cartographer/transform/proto/transform.proto";
// Serialized state of a mapping::TrajectoryNode::Data.
message TrajectoryNodeData {
int64 timestamp = 1;
transform.proto.Quaterniond gravity_alignment = 2;
sensor.proto.CompressedPointCloud
filtered_gravity_aligned_point_cloud = 3;
sensor.proto.CompressedPointCloud high_resolution_point_cloud = 4;
sensor.proto.CompressedPointCloud low_resolution_point_cloud = 5;
repeated float rotational_scan_matcher_histogram = 6;
transform.proto.Rigid3d local_pose = 7;
}
cartographer/mapping/trajectory_node.h文件:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30struct TrajectoryNode {
struct Data {
common::Time time;
// Transform to approximately gravity align the tracking frame as
// determined by local SLAM.
Eigen::Quaterniond gravity_alignment;
// Used for loop closure in 2D: voxel filtered returns in the
// 'gravity_alignment' frame.
sensor::PointCloud filtered_gravity_aligned_point_cloud;
// Used for loop closure in 3D.
sensor::PointCloud high_resolution_point_cloud;
sensor::PointCloud low_resolution_point_cloud;
Eigen::VectorXf rotational_scan_matcher_histogram;
// The node pose in the local SLAM frame.
transform::Rigid3d local_pose;
};
common::Time time () const { return constant_data->time; }
// This must be a shared_ptr. If the data is used for visualization while the
//node is being trimmed, it must survive until all use finishes.
std::shared_ptr<const Data> constant_data;
// The node pose in the global SLAM frame.
transform::Rigid3d global_pose;
};
后端是一个 Pose Graph 的优化。通过调整 nodes 和 submaps 之间的约束关系来优化最终的图。Constraints 直觉上来感觉就是由一根根小绳子将所有的 nodes 给捆起来,pose adjustement 就是把这些小绳子给全部接起来。这也就是所谓的 Pose Graph。
Rviz 中可以对这些 Constraints 进行可视化,这对调试 Global SLAM 来说是非常方便的。
还可以开启
POSE_GRAPH.constraint_builder.log_matches来看关于 constraints builder 的 report。
约束分为非全局约束与全局约束:
- 非全局约束也被称作 (也被称作是 inter submaps constraints)。它在一条 trajectory 上离得近的 nodes 之间被自动构建。直觉上来看,这些约束使得 trajectory 的局部结构是一致的。
- 全局约束 (也被称作是 loop closure constraints 或者 intra submaps contraints) 的运行:通常是在一个新的 new submap 和之前的 nodes 之间进行搜索,当满足空间上足够的相近(被一个 search window 限定)以及一个极强的 scan match 结果。直观的来讲,相当于在两个绳子 (约束) 之间打一个结点使得两根绳子里的更近。
1 | |
官方默认配置:
pose_graph.lua
1 | |
// TODO ICRA RM 两台机器人,这一点可以考虑
Cartographer 不止可以单单在单个轨迹上 loop closure,还可以在多个机器人的多个轨迹上 align。这个部分的文档 the parameters related to “global localization” out of the scope of this document.
为了限制 constraints 的数量(也是降低计算力),Cartographer 对这些 node 做了一个下采样,通过 POSE_GRAPH.constraint_builder.sampling_ratio 参数来控制。下采样过度会导致约束缺失以及不容易进行 loop closure,下采样力度过小会导致 Global SLAM 的运行速度过慢以及不能实时的 loop closure。
官方默认配置:
pose_graph.lua
1 | |
当一个 node 和一个 submap 进行 constraint building 的时候,通过的是一个叫做 FastCorrelativeScanMatcher 的机制。这个 scan matcher 是 Cartographer 的独创并且使得 real-time loop closures scan matching 成为可能。它引入了分支界限法(Branch and bound),可以在不同分辨率的地图网格上进行工作并且非常有效的去除误匹配。关于这个在 Cartographer 的论文中被详细描述了。所用的搜索树的深度是可以被控制的。
1 | |
官方默认配置:
pose_graph.lua
1 | |
一旦 FastCorrelativeScanMatcher 达到一定的效果的时候(大于POSE_GRAPH.constraint_builder.min_score参数值),会把它再继续扔到 CeresScanMatcher 中来进行 refine。
1 | |
官方默认配置:
pose_graph.lua
1 | |
The Optimization Problem
当 Cartographer 运行优化问题的时候,Cartographer 会通过多个残差项来对 submaps 进行调整。每一项残差通过被加权的 cost function 来计算(和 SLAM 中常见的做法一样)。这些每一个 cost function 取自多个数据源,全局 (回环) 约束 global (loop closure) constraints,非全局 (scan match) 的约束 the non-global (matcher) constraints,IMU 的测量值 IMU acceleration and rotation measurements,local SLAM 的粗略的 pose 估计 local SLAM rough pose estimations,外部的 odometry 信息或者 GPS 等 an odometry source or a fixed frame (such as a GPS system)。可通过下面项来进行配置:
1 | |
TODO ?
One can find useful information about the residuals used in the optimization problem by toggling
POSE_GRAPH.max_num_final_iterations
官方默认配置:
pose_graph.lua
1 | |
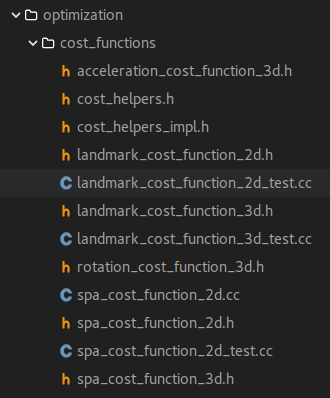
在代码中,各种 cost function 的定义文件路径:

Cartographer 提供了如下的 cost functions:
全局优化时对于 IMU 数据的处理
Global optimization 对 imu 的 pose 信息提供了更多的灵活性。默认的 Ceres 会优化你 IMU 和 tracking frame 之间的外参。如果你不信任你的 imu 的数据的话,Ceres’ global optimization 的结果可以被记录然后来用来优化它俩之间的外参矩阵。如果 Ceres 不能够很好的优化 IMU 的 pose (它俩之间的外参矩阵) 或者你非常信任你校准的它俩之间的外参矩阵的话,可以当做常量来使用自己标定的外参矩阵。
1 | |
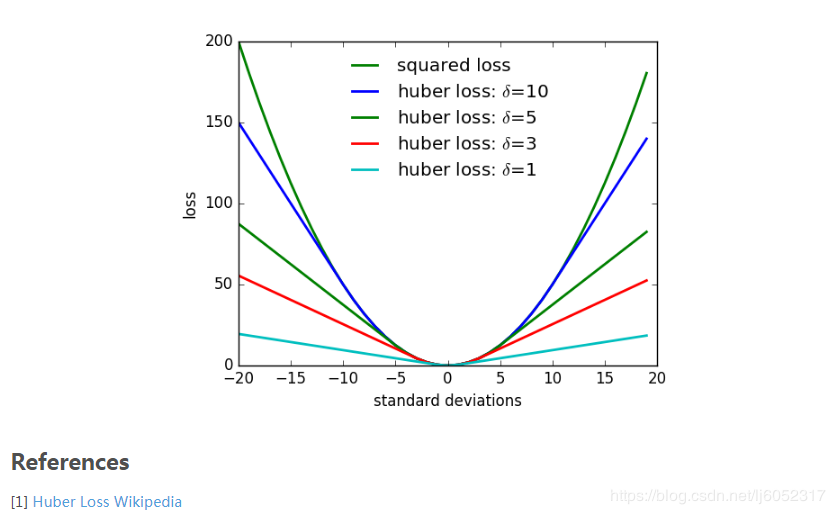
Huber loss
在 residuals 中,采用 Huber loss function 从而控制 outliers 的影响。Huber loss function 的 Huber scale 是定的,通过下面参数指定。
1 | |
这个值选的越大,潜在的 outliers 对系统的影响可能就越大。
huber loss 是一种优化平方 loss 的一种方式,使得 loss 变化没有那么大。

最终的全局优化
一旦 当 trajectory 完成后,Cartographer 经常会运行一个新的全局优化,迭代的次数通常比之前的要多得多。这样做的原因是要尽可能的去优化最终建图的效果,并且通常并没有实时性的要求。所以选择大量的迭代是正确的选择.
1 | |
附: PointCloud2 消息类型的数据格式
手动解析点云数据时不可以直接解析,因为在 field 里是以二进制方式存储的,可以通过 ros 包里的工具来进行解析
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!联系作者。