模式识别入门(一) - 模式识别概论
本学期选修了学校自动化学院的张绍武教授《模式识别》课程。此为期末总结时候的复习总结。此篇介绍了模式识别入门的一些常识与概念。(由于期末复习来不及了… 后面停更了)
Chapter 1 概论
1.1 模式识别基本概念
1.1.1 模式识别的基本定义
-
样本 (sample, object)
一类事物的一个具体体现,对具体的个别事物进行观测所得到的某种形式的信号。一般用向量表示.
-
模式 (pattern)
表示一类事物.
样本是具体的事物,而模式是对同一类事物概念性的概括
-
模式类与模式联合使用时,模式表示具体的事物,而模式类则是对这一类事物的概念性描述
模式与模式类的例子:
- 模式类:老年人;模式:王老太,老头,老太
- 模式类:老头;模式:王老头
- 模式类:老太;模式:王老太
模式识别 (Pattern Recognition)
主要研究相似与分类的问题,用计算机实现对人和各种事物或者现象的分析,描述,判断与识别.
> Pattern recognition:
is the study of how machines can observe the environment, learn to distinguish patterns of interest from their background, and make sound and reasonable decisions about the categories of the patterns. (Anil K. Jain)
模式识别的作用与目的
将某一具体事物正确的归入某一类别。也就是从样本到类别的映射.

1.1.2 模式识别的发展史
- 1929 年 G. Tauschek 发明阅读机,能够阅读 0-9 的数字
- 30 年代 Fisher 提出统计分类理论,奠定了统计模式识别的基础。因此,在 60~70 年代,统计模式识别发展很快,但由于被识别的模式愈来愈复杂,特征也愈多,就出现 “维数灾难”. 随着计算机运算速度的迅猛发展,这个问题得到一定解决。统计模式识别仍是模式识别的主要理论
- 50 年代 Noam Chemsky 提出形式语言理论,美籍华人付京荪提出句法结构模式识别
- 60 年代 L.A. Zadeh 提出了模糊集理论,模糊模式识别理论得到了较广泛的应用
- 80 年代 Hopfield 提出神经元网络模型理论。人工神经元网络在模式识别和人工智能上得到较广泛的应用
- 90 年代 V.N. Vapnik 提出了小样本学习理论,支持向量机也受到了很大的重视
- 2012 年后,Deep Learning.
1.1.3 关于模式识别的国内,国际学术组织
-
1973 年 IEEE 发起了第一次关于模式识别的国际会议 “ICPR”, 成立了国际模式识别协会 --“IAPR”, 每 2 年召开一次国际学术会议
-
1977 年 IEEE 的计算机学会成立了模式分析与机器智能 (PAMI) 委员会,每 2 年召开一次模式识别与图象处理学术会议
-
CVPR, PRCV 等
-
电子学会,通信学会,自动化学会,中文信息学会
(TODO)
1.2 模式识别系统
执行模式识别的计算机系统称为模式识别系统。该系统被用来执行模式分类的具体任务.
一个典型的模式识别系统如下图所示结构框图组成

一般由 数据获取,预处理,特征提取选择,分类器设计及分类决策 五部分组成。分类器设计在 训练过程 中完成,利用样本进行训练,确定分类器的具体参数。而分类决策在 识别过程 中起作用,对待识别的样本进行分类决策.

流程样例:
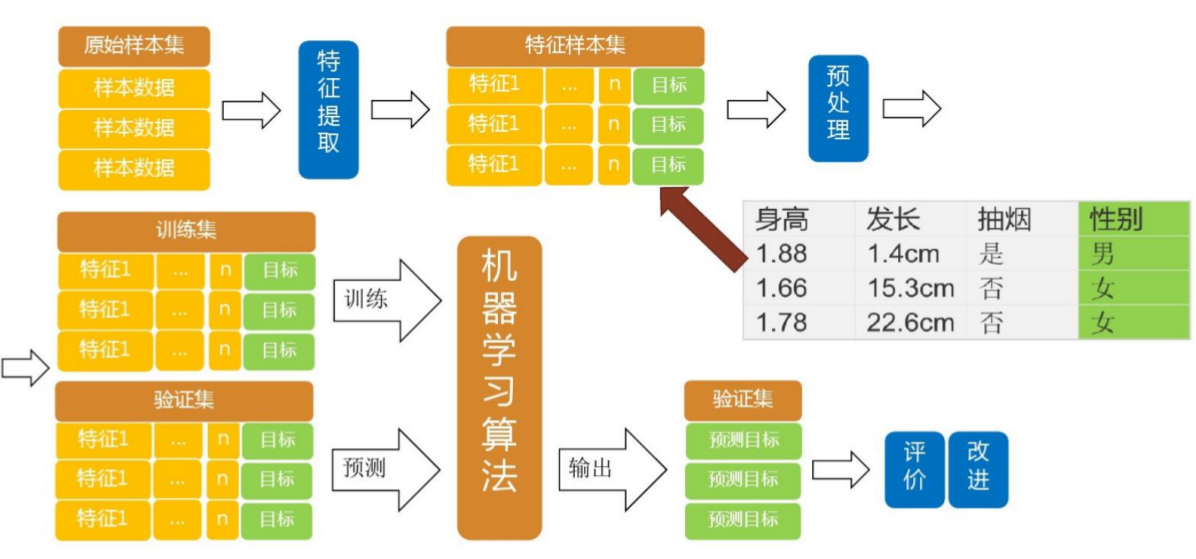
说明:
- 这一系统构造适合于统计模式识别,模糊模式识别,人工神经网络中有监督方法
- 对于结构模式识别方法,只需用基元提取代替特征提取与选择
- 对于聚类分析,分类器设计与决策合二为一, 一步完成
步骤:
-
信息获取 (data acquisition)
-
预处理 (preprocessing)
目的:去除所获取信息中的噪声,增强有用的信息,及一切必要的使信息纯化的处理过程
常用技术: A\D , 二值化,一维信号滤波去噪,及图象的平滑、变换、增强、恢复、滤波等处理
-
特征选择与提取 (feature selection and extraction)
一般说来它包括将所获取的原始量测数据转换成能反映事物本质,并将其最有效分类的特征表示
样本及模式都是用特征来描述,识别与训练在 特征空间 中进行。量测仪器或传感器获取的原始数据组成的空间叫 测量空间.
特征选择与提取模块的功能是对所获取的信息实现 ** 从测量
空间到特征空间的转换 **找到合适的特征描述对识别的可靠性,计算复杂度、有效性都是十分重要的
-
分类器设计 (classifier design)
分类器设计的主要功能是通过训练确定判决规则,按此类判决规则分类时,错误率最低。把这些判决规则建成标准库.
-
分类决策 (classification decision)
在特征空间中对被识别的对象进行分类。分界线的类型可由设计者直接确定,也可通过训练过程产生,但是这些分界线的具体参数则利用训练样本 经训练过程确定
-
分类决策是对事物辨识的最后一步,其主要方法是计算待识别事物的属性,分析它是否满足是某类事物的条件
-
对于每个事物来说,由它的属性得到它的描述,表示成相应的特征向量,它在特征空间中表示成一个点,称为数据点
-
特征空间的分布中往往表现出同类事物的特征向量聚集在一起,聚集在一个相对集中的区域,而不同事物则分别占据不同的区域
-
待识别的事物,如果它的特征向量出现在某一类事物经常出现或可能出现的区域内,该事物就被识别为该类事物
-
在特征空间中,哪个区域是某类事物典型所在区域,需要用数学式子划定,这样一来,满足这种数学式子与否就成为分类决策的依据
-
如何 确定这些数学式子 就是分类器设计的任务,而一旦这种数学
式子确定后,分类决策的方法也就确定了
-
1.3 模式识别方法
-
模板匹配方法 (templete matching)
-
统计方法 (statistical pattern recognition)
-
神经网络方法 (neural network)
-
结构方法 (句法方法) (structural pattern recognition)
-
模糊模式识别 (Fuzzy pattern recognition)
-
逻辑推理方法 (Logic inference)
(TODO 详细的后面补充)
1.4 模式识别应用
略
1.5 模式识别基本问题
1.5.1 模式 (样本) 表示方法
-
向量表示:假设一个样本有 n 个变量 (特征)
-
矩阵表示
-
几何表示
1.5.2 模式类的紧致性
-
紧致集:同一类模式类样本的分布比较集中,没有或者临界样本很少,这样的模式类称为 紧致集
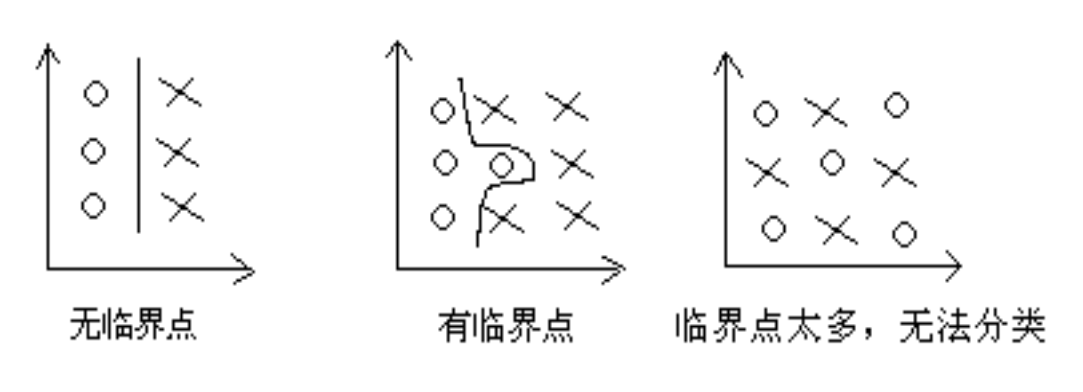
-
临界点 (样本): 在多类样本中,某些样本值有微小的变化时就变成了另一类样本称为 临界样本 (点)
-
紧致集的性质:
- 与样本总数相比,临界点的数量非常少
- 集合内任意两点可以用光滑线连线,在线上的点属于同一集合
- 集合内的每一个点都有足够强大的领域,在邻域内包含同一集合的点
-
模式识别的要求:
- 满足紧致集,才能很好的分类
- 如果不能满足紧致集,就要采取变换的方法来使其满足紧致集.
只要各个模式类是可分的,总存在这样一个空间,使变换到这个空间中的集合满足紧致集的要求
1.5.3 相似与分类
两个样本 之间的相似度量满足以下要求:
- 应该为非负值
- 样本本身相似性度量应该最大
- 度量应满足对称性
- 在满足紧致性的条件下,相似性应该是点间距离的单调函数
1.5.3.1 用各种距离表示相似性
已知两个样本:
-
绝对值距离:
-
欧几里得距离:
-
明考夫斯基距离:
其中当 q=1 时为绝对值距离,当 q=2 时为欧氏距离
-
切比雪夫距离:
切氏距离为 q 趋向于无穷大时的明氏距离的极限情况
-
马哈拉诺比斯距离 (Mahalanobis diatance):
其中 为特征向量, 为协方差矩阵。使用条件为样本符合正态分布
-
夹角余弦:
即之间夹角小的样本具有相似性,可分为一类.
-
相关系数:
为 的均值.
注意: 在求相关系数之前,要将数据标准化 (极差标准化,方差标准化)
1.5.3.2 分类的主观性和客观性
-
分类带有主观性:目的不同,分类不同
例:鲸鱼、牛、马从生物学的角度来讲都属于哺乳类,但是从产业角度来讲鲸鱼属于水产业,牛和马属于畜牧业
-
分类的客观性:科学性
判断分类必须有客观标准,因此分类是追求客观性的。但主观性也很难避免,这就是分类的复杂性.
1.5.3.3 特征的生成
特征是决定相似性与分类的关键,寻找合适的特征是认知与识别的核心问题。可粗略地分为底层、中层、高层 3 个层次.
-
低层特征:
- 无序尺度:有明确的数量和数值.
- 有序尺度:有先后、好坏的次序关系,如酒分为上,中,下三个等级.
- 名义尺度:无数量、无次序关系,如有红、黄两种颜色.
-
中层特征:
- 经过计算、变换得到的特征
-
高层特征:
-
在中层特征的基础上有目的的经过运算形成
例如:椅子的重量 = 体积 * 比重,体积与长、宽、高有关;比重与材料、纹理、颜色有关。这里低、中、高三层特征都有了.
-
1.5.3.4 数据标准化
-
极差标准化
极差:一批样本中,每个特征的最大值与最小值之差.
极差标准化两种方式:
-
方差标准化
为方差:
方差标准化:
-
归一化标准化
标准化的方法很多,原始数据是否应该标准化,应采用什么方法标准化,都要根据具体情况来定.
Reference: 西北工业大学自动化学院张绍武教授《模式识别》课程 PPT
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!联系作者。