本篇介绍使用 K-L 变换实现一个简单的人脸识别算法。完整的代码、报告和数据见 Github:https://github.com/kehanXue/pca-face-recognition 。K-L 变换也常称为主成分变换 (PCA),是一种基于图像统计特性的变换,它的协方差矩阵除对角线以外的元素都是零 (所以大家也叫它最佳变换),消除了数据之间的相关性。
K-L 变换也常称为主成分变换 (PCA),是一种基于图像统计特性的变换,它的协方差矩阵除对角线以外的元素都是零 (所以大家也叫它最佳变换),消除了数据之间的相关性,从而在信息压缩方面起着重要作用。
在模式识别和图像处理中一个主要的问题就是降维,在实际的模式识别问题中,我们选择的特征经常彼此相关,在识别这些特征时,数量很多,大部分都是无用的。如果我们能减少特征的数量,即减少特征空间的维数,那么我们将以更少的存储和计算复杂度获得更好的准确性。如何寻找一种合理的综合性方法,使得:
减少特征量的个数。
尽量不损失或者稍损失原特征中所包含的信息。
使得原本相关的特征转化为彼此不相关 (用相关系数阵衡量)。
K-L 变换 即主成分分析就可以简化大维数的数据集合。K-L 变换以原始数据的 协方差矩阵的归一化正交特征矢量构成的正交矩阵 作为变换矩阵,对原始数据进行正交变换,在变换域上实现数据压缩。它具有去相关性、能量集中等特性,属于均方误差测度下,失真最小的一种变换,是最能去除原始数据之间相关性的一种变换。它还可以用于许多图像的处理应用中,例如:压缩、分类、特征选择等。
K-L 变换的实质就是去除各维度之间的相关性。就是建立新的坐标系,将原本高度相关的数据在新坐标系下的协方差矩阵除对角线以外的元素都是零。从坐标系的角度来看,图像的矩阵可以看作为二维平面上一组像素点坐标的集合,变换的结果 Y 可以看作是图像矩阵 X 在一个新的坐标系下的相同像素点的集合。该新的坐标系为原坐标系的旋转,旋转矩阵即为 K-L 变换矩阵。
在原坐标系下的 x 和 y 具有非常强的相关性,而变换后两者之间的相关性被去除。
K-L 变换的目的,即在于找出使得 X 矢量中的各个分量相关性降低或去除的方向,对图像进行旋转,使其在新空间的坐标轴指向各个主分量方向 —— 主成分分析或者主成分变换。扩展至多维空间,K-L 变换可实现多维空间中的去相关,并将能量集中在少数主分量上。
构建新坐标系的过程就是主成分变换的过程。y 代表新坐标系的坐标点,x 代表原来坐标系的点。
y = W ∗ x y=W * x
y = W ∗ x
其中 W W W W W W x x x
PCA 则是选取协方差矩阵前 k 个最大的特征值的特征向量构成 K-L 变换矩阵。保留多少个主成分取决于保留部分的累积方差在方差总和中所占百分比(即累计贡献率),它标志着前几个主成分概括信息之多寡。实践中,粗略规定一个百分比便可决定保留几个主成分;如果多留一个主成分,累积方差增加无几,便不再多留。
假设一幅人脸图像包含 N N N N N N x x x x i ( i = 1 , . . . , M ) {x_i (i=1,...,M)} x i ( i = 1 , . . . , M ) C C C
λ 1 ⩾ λ 2 ⩾ … ⩾ λ r \lambda_{1} \geqslant \lambda_{2} \geqslant \ldots \geqslant \lambda_{\mathrm {r}}
λ 1 ⩾ λ 2 ⩾ … ⩾ λ r
其对应的特征向量为 μ k \mu_{\mathrm {k}} μ k
有了这样一个由 “特征脸” 张成的降维子空间,任何一幅人脸图像都可以向其投影得到一组坐标系数,这组系数表明了该图像在子空间中的位置,从而可以作为人脸识别的依据。
计算数据库中每张图片在子空间中的坐标,得到一组坐标,作为下一步识别匹配的搜索空间。
计算新输入图片在子空间中的坐标,采用最小距离法,遍历搜索空间,得到与其距离最小的坐标向量,该向量对应的人脸图像即为识别匹配的结果。
选取数据集,并将其读入.将每一张图像均 reshape 为列向量 X i X_i X i
X = ( X 1 , X 2 , … , X n ) \mathbf {X}=\left (\mathbf {X}_{1}, \mathbf {X}_{2}, \ldots, \mathbf {X}_{n}\right)
X = ( X 1 , X 2 , … , X n )
求均值向量
μ = 1 n ∑ i n X i \boldsymbol {\mu}=\frac {1}{n} \sum_{i}^{n} \boldsymbol {X}_{i}
μ = n 1 i ∑ n X i
求中心化后的数据矩阵
C = ( X 1 − μ , X 2 − μ , … , X n − μ ) \mathrm {C}=\left (\mathbf {X}_{1}-\boldsymbol {\mu}, \mathbf {X}_{2}-\boldsymbol {\mu}, \ldots, \mathbf {X}_{n}-\boldsymbol {\mu}\right)
C = ( X 1 − μ , X 2 − μ , … , X n − μ )
求 C ⊤ C C^{\top} \mathrm {C} C ⊤ C k k k e i \mathbf {e}_{\mathbf {i}} e i k k k W W W
W = ( e 1 , e 2 , … , e k ) W=\left (\mathbf {e}_{1}, \mathbf {e}_{2}, \ldots, \mathbf {e}_{k}\right)
W = ( e 1 , e 2 , … , e k )
计算每一幅图像的投影 (k k k
Y i = W ⊤ ( X i − μ ) Y_{i}=W^{\top}\left (X_{i}-\mu\right)
Y i = W ⊤ ( X i − μ )
计算待识别的人脸的投影 (k 维列向量), 设待识别的人脸为 Z Z Z
ch Z = W ⊤ ( Z − μ ) \operatorname {ch} \mathbf {Z}=\mathbf {W}^{\top}(\mathbf {Z}-\boldsymbol {\mu})
c h Z = W ⊤ ( Z − μ )
遍历搜索进行匹配,找到最近邻的人脸图像,根据标签得到 Z Z Z
Y j = min ∣ ∣ Y i − ch z ∣ ∣ Y_{j}=\min | | Y_{i}-\operatorname {ch} z| |
Y j = min ∣ ∣ Y i − c h z ∣ ∣
graph TB;
A("读入训练集数据,每个人 10 张照片中选取 8 张作为训练集")-->B("求均值向量 avgX");
B-->C("训练数据中心化");
C-->D("进行 K-L 变换,求出特征矩阵与所有特征值");
D-->E("进行主成分分析,选取构成能力 95% 的特征值");
E-->F("得到变换矩阵 W,计算出特征脸");
F-->G("将训练数据投影到该新的特征空间中");
G-->H("取每个人的两张照片构成测试集,计算准确率");
Fig.1.2.1 训练数据中心化后的图片.
这里展示其中 20 张训练数据中心化后的人脸样例.
Fig.1.2.2 特征脸样例
这里展示其中 20 张特征脸样例.
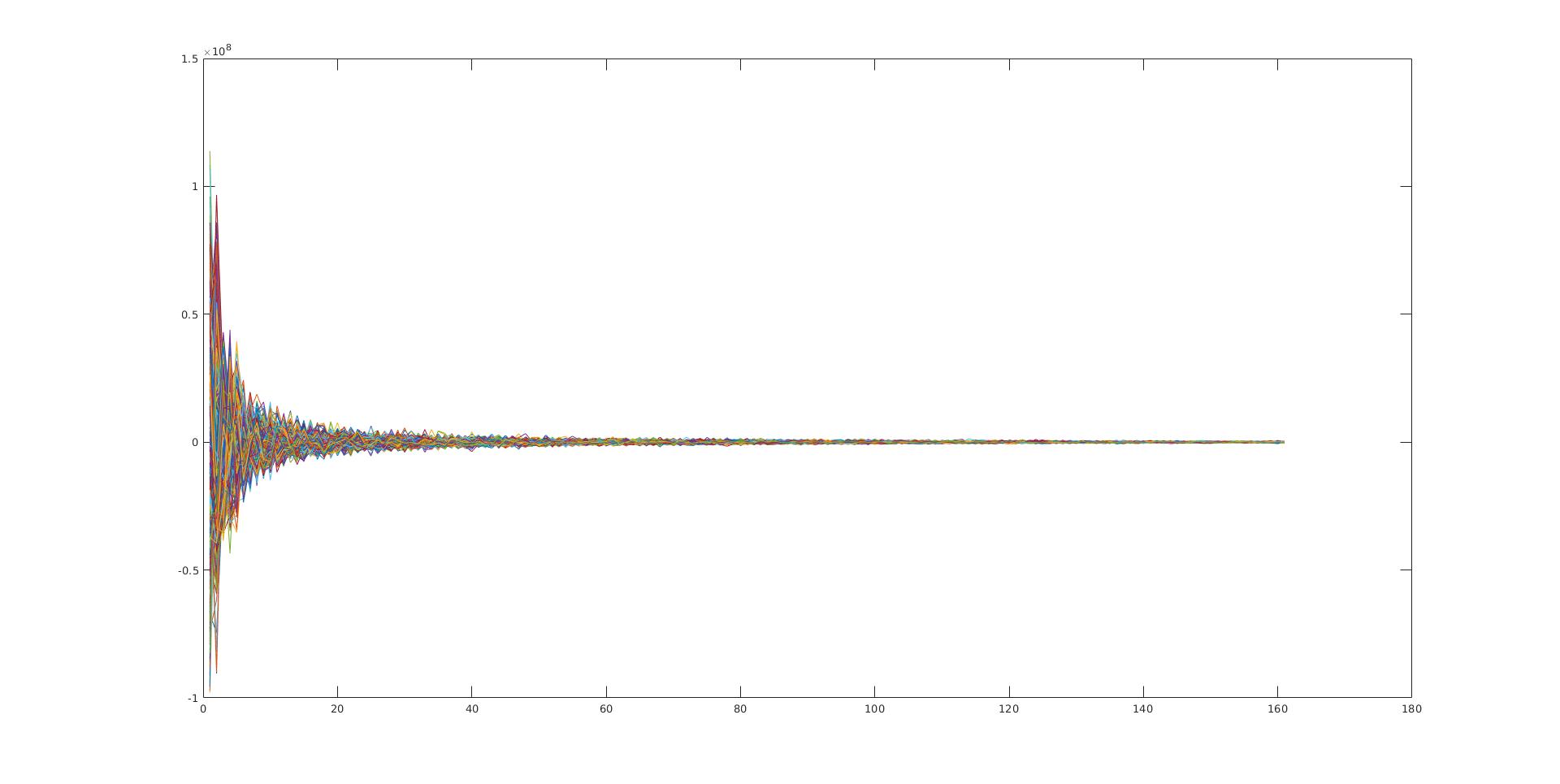
Fig.1.2.3 训练数据投影到新的特征空间后的数据分布图
训练数据投影到新的特征空间后对应的新的数据矩阵,横轴表示维度 (选取的主分量的数量), 纵轴代表投影后的各个分量的大小,可以看出靠前的分量占得总能量更大.
我们的训练数据集中一共有 40 个人的照片,每个人的照片各十张。我们将每个人的后两张图片作为测试样本集。然后根据前面通过改变训练样本的数量来观察其对分类精确度的影响。我们通过改变每个人选取的照片数量 n n n n = 3 , 4 , . . . , 8 n=3,4,...,8 n = 3 , 4 , . . . , 8
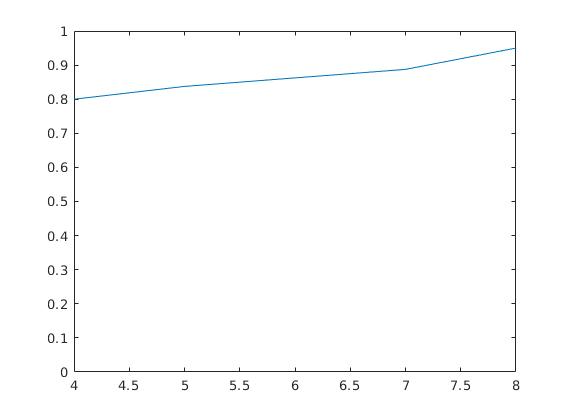
Fig.1.2.4 模型的精确度随训练数据集的数量的变化.
可见,随着训练样本数的增加,模型的精确度也在上升,其中当每个人的照片至少取 4 张时才可以开始进行比较好的判别.
matlab 程序代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 clear'orl_faces' );1 , 1 ); zeros (2 , 2 );zeros (1 , 1 );0 ;for train_data_nums = 6 :-1 :2 0 ;type = 0 ;0 ,0 );for i = 4 : length (db)i ).folder '/' db (i ).name]);type = type + 1 ;for j = 3 : length (fi)-train_data_nums1 ;i - 2 , j - 2 } = imread ([fi (j ).folder '/' fi (j ).name]);type ;if num == 1 size (face {i - 2 , j - 2 });end 1 : imageLen *imageWid, num) = double (reshape (face {i - 2 , j - 2 }, [imageLen* imageWid, 1 ]));end 1 , type ) = i -3 ;end size (allData);mean (allData, 2 );for num = 1 :allDataColsend 1 ;0 ;while (proportion < 95 )1 ;end 1 ;1 :numOfLatent);zeros (1 , 1 );0 ;MNIST 数据集来自美国国家标准与技术研究所,National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成,其中 50 0 ;0 ;for i = 4 : length (db)i ).folder '/' db (i ).name]);1 ;for j = length (fi)-1 : length (fi)1 ;j ).folder '/' fi (j ).name]);reshape (imgTest, [imageLen * imageWid, 1 ]);realmax ('double' );for k = 1 :allDataColsif (dis> temp)end end if labelMap (aimOne) == type_index1 ;end end end 1 ;3 ) = accCnt/testNum;end